Engineering
Making Public Notice Accessible Through Machine Learning
By Sajan Mehrotra, Summer Intern · August 28, 2020
The public notice system stems from the philosophy that public interest information should not just be easily accessible to citizens, but should be proactively distributed to communities. At first, this meant local officials posted relevant information in town squares. For the last few centuries, it has meant that governments and businesses place these updates in local newspapers.
Now a new iteration of the system: in partnership with press associations, Column supports newspapers in the online display of public notice and makes them accessible via statewide databases.

Column’s next challenge is simplifying these notices, which often consist of complex legal language. To tackle this problem, we’re applying machine learning to decipher this legalese and extract the most relevant information.

As an intern at Column this past summer, I was lucky enough to play a substantive role in this project, and the company tasked me with helping productionize this machine learning pipeline.
Understanding the Data
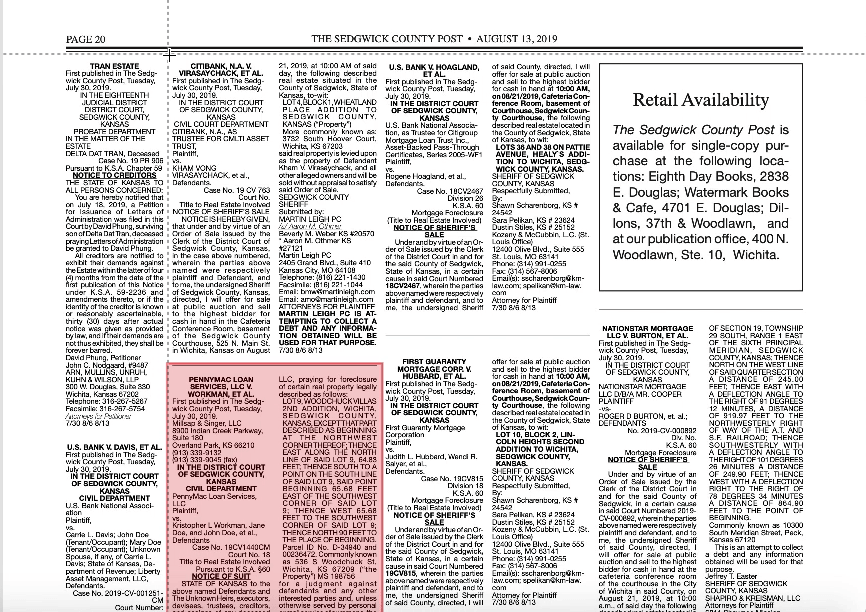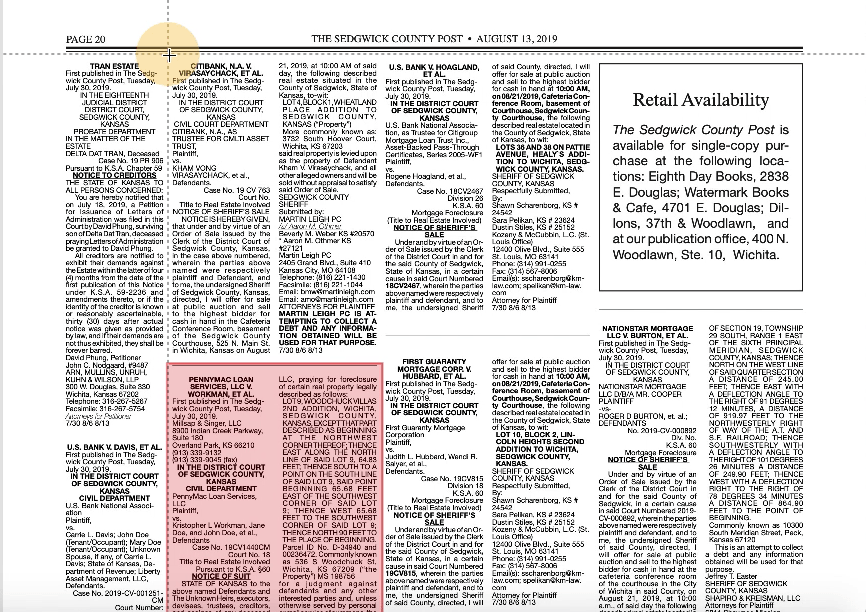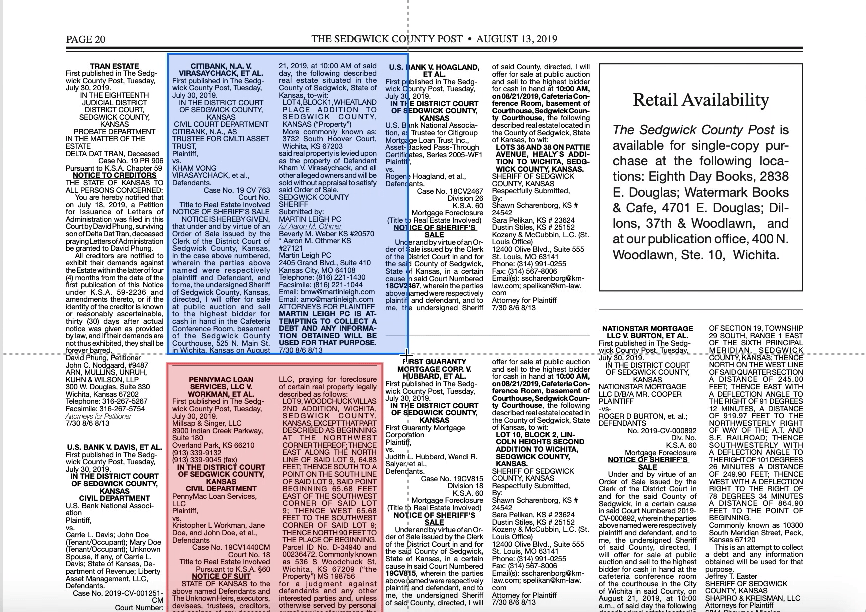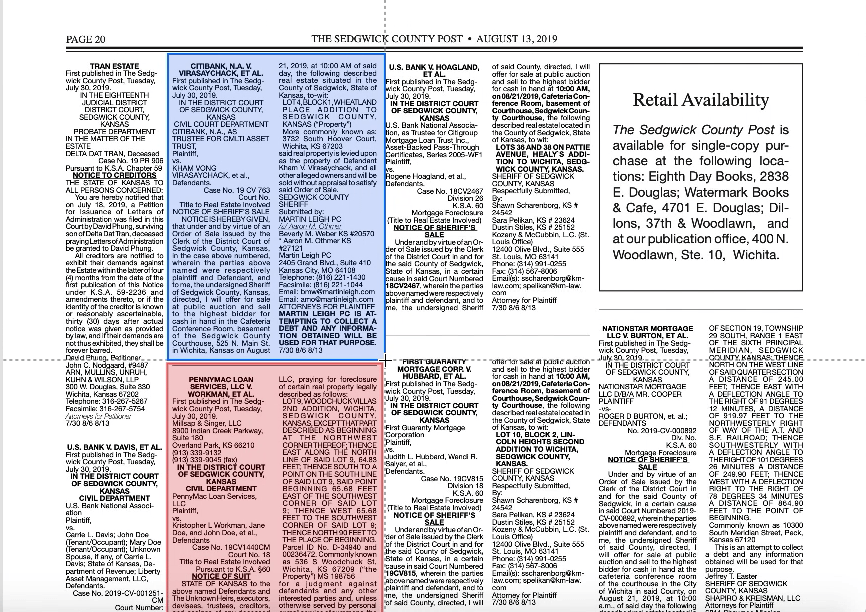
We began with “Request for Proposal” (RFP) notices, which announce the start of a bid process for local governments. These notices serve to increase competition - if only a handful of people know a government is looking for contracts, then very few companies will bid on the project. By publishing notices in local newspapers, governments can make their requests more widely known. In contrast, a lack of awareness fosters corruption, because if RFP’s aren’t publicized, local officials effectively have control over who knows about - and therefore who can bid on - government business.
Using modern technology, we can build on these efforts. Our goal was to go from an unstructured newspaper page of notices to organized information in named entities on our statewide sites.
Our Approach
We knew that we would need two machine learning models to build this pipeline:
- First, we wanted a computer vision model to separate public notices on the same newspaper page, so we could manipulate them one at a time.
- Second, we used an entity extraction model that pulls out the relevant information from the separated notices.
Our most important initial insight was that the tools for building both of these models had been productized by the Google Cloud service AutoML. This means that we could get extremely performant ML models up and running in the span of days, not months or years. AutoML effectively reduces the previously hard problems of object detection and named entity extraction to an entirely non-technical problem: labeling training data
So, the problem was organizational, rather than technical. To build a prototype for the computer vision model, we estimated we needed about 100 high-quality labels, which translated to roughly 20 hours of work. We choose this number pretty arbitrarily - high enough to provide some indication of whether this method would work, but low enough so that failure wouldn’t waste too much time. For the entity extraction model, we wanted to meet Google AutoML’s minimum requirement of 100 labels per entity, which we similarly thought would give us an indicator of success without too much time investment.
I relied on other Column interns for help. Oliver Kao, Roz Stengle, Hunter Bigge, and Andrew Mandelstam all put in time to make this project succeed, taking on a portion of the labeling tasks. The project would not have been possible if not for their contributions, which significantly improved the project’s timeline and allowed us to start iterating the process before the end of the summer. I introduced a replicable structure to our labeling system by recording a Loom documenting best practices, and by introducing LabelBox to manage assignments.
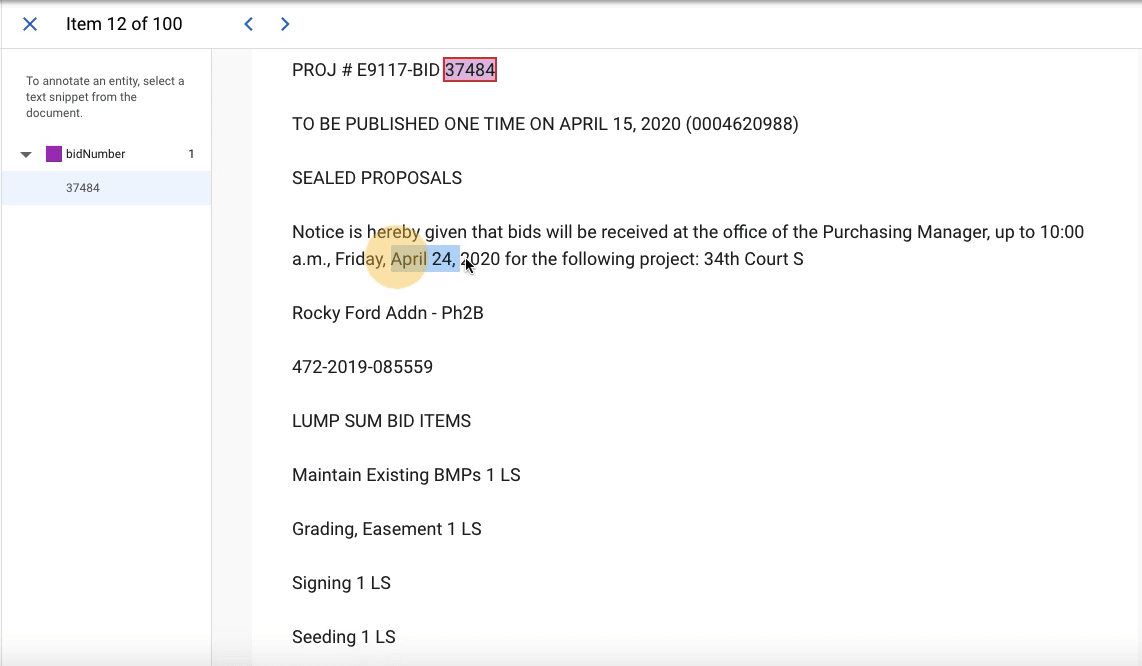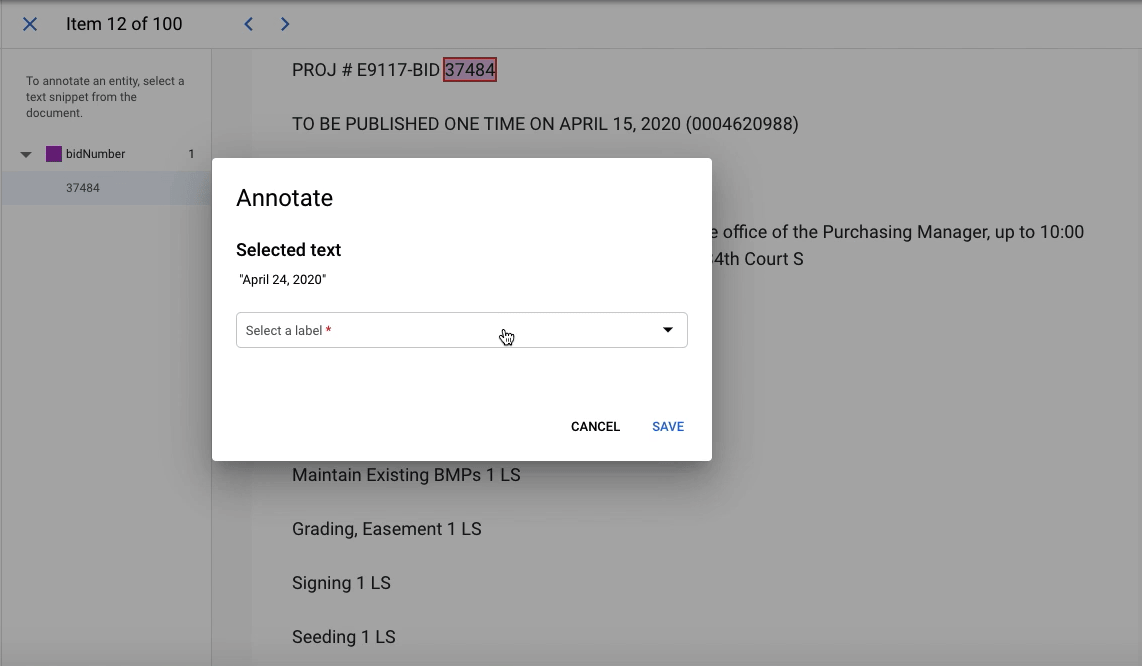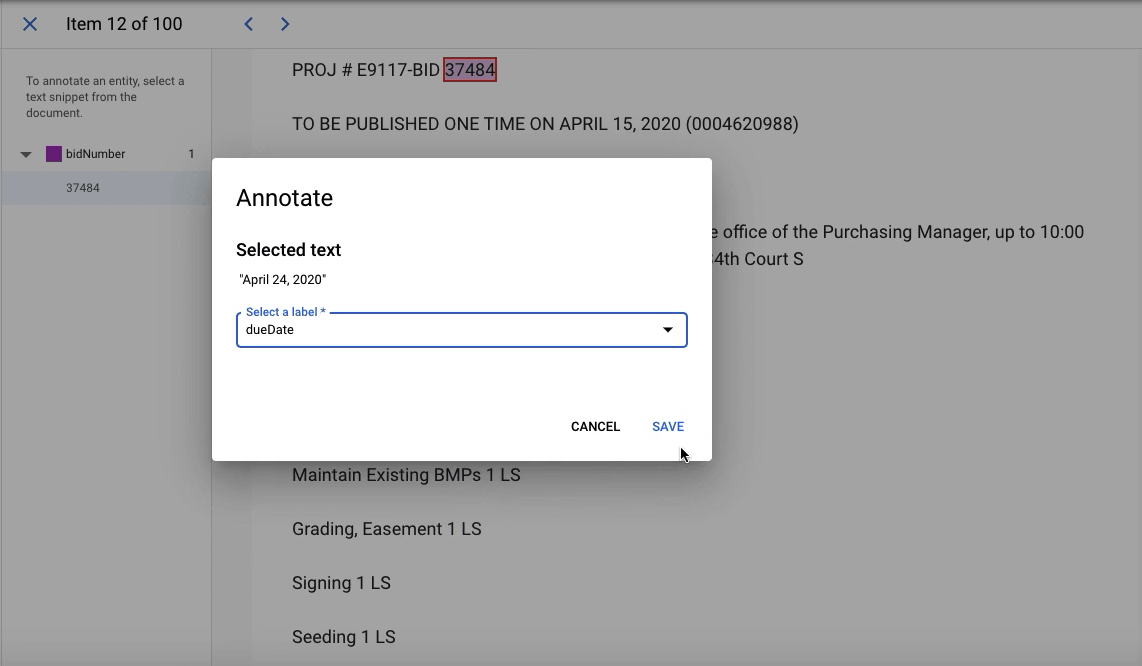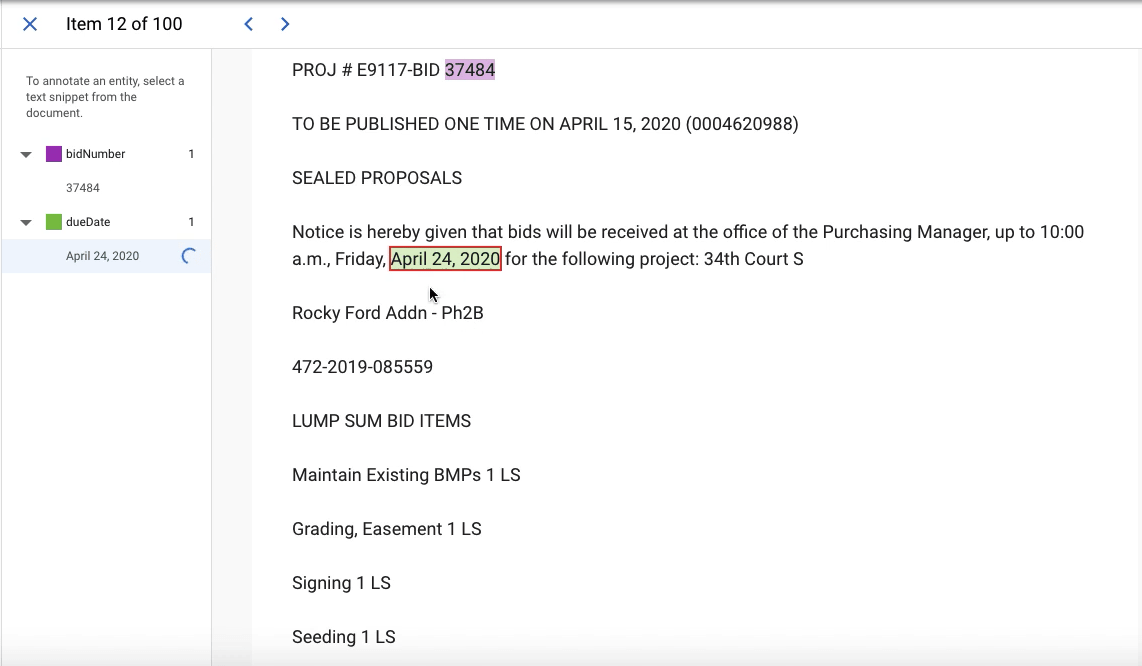
Object Detection
Our first version of the computer vision model had surprisingly impressive results, especially given the relatively small training data set. The model had 98.15% precision and 89.83% recall. This means that when the model detected a public notice, it was correct 98.15% of the time; when there was a public notice on the page, the model found it 89.83% of the time.
At first, this model was tasked with just detecting a particular type of public notice (those that dealt with foreclosure hearings). We thought we could improve the scores if we just asked the model to indiscriminately detect every public notice, and then classify them later. When trying this method, the vision model had 95.15% accuracy, and 97.03% recall - all based on the same 100 training documents. While these results were impressive, we wanted to dig deeper to figure out how to boost our precision and recall numbers.
Identifying and Resolving Systemic Errors
In exploring error patterns in the computer vision model, we found that different newspapers have slightly different layouts. The model performed extremely well on one type of layout (type A), but not the other (type B).


Looking back at our training data, we found that the model was trained on type A newspaper pages far more than type B pages. Looking at the Kansas Press Association website, we found that this is largely because type A newspapers are far more abundant than type B. We concluded that to make our training data remain reflective of the natural distribution of type A and B newspapers, while simultaneously giving the model enough type B pages to work with, we needed to expand our training data significantly. However, the prototype succeeded in detecting public notices on newspapers it was more familiar with, so we expect this new training data to improve the model’s performance on type B papers.
Entity Extraction
On the entity extraction model, we had 56.9% accuracy and 64.71% recall. These numbers were less encouraging, so we wanted to understand if there were patterns in the model’s mistakes.
Identifying and Resolving Systematic Errors
After closer examination, the scary performance numbers for this model appeared to be an underestimate of the model’s potential. Similar to the object detection model, our training data was biased in favor of more common formats even if our dataset reflected reality (meaning, the natural distribution of RFP notices among newspapers). One of the formatting differences that appeared to cause issues was length - the model performed well on shorter notices, but poorly on longer ones. We believe this is because in the shorter notices, there is less information. For example, there is usually only one date (the due date), whereas longer notices may contain multiple dates (ex. the due date and the date of a pre-bid meeting); this means that while the model can just return any date in the shorter notices, the model has to learn to distinguish between dates in the longer notices.


However, the model performs incredibly well on short notices with common formats. Similar to the object detection model, we took this to mean that the model will perform well on notice formats that are well represented in the training data. Under this theory, the obvious solution is to build a more expansive training dataset.
Productionizing Data Labeling
We are currently in the process of doing another iteration of training to improve the models; we will continue this iteration until we see clear diminishing returns on the model’s recall and precision numbers. The main task ahead is to create a system for constructing expansive, well-labeled datasets in a cost-effective way to make this iteration feasible.
Once we productionize data labeling, we’ll have built a machine learning pipeline to take unstructured newspaper pages of complex legalese and convert them into organized data reflecting the key information from each notice. Although the project is complex, the principle behind it is simple: public interest information should be as accessible as possible. The same philosophy which led local officials to post updates in town squares many centuries ago pushed Column engineers today to apply cutting edge technology to the age old system of public notice.
© 2020 Column, PBC. All rights reserved.